
Rendimiento y velocidad de carga web
Existen herramientas para probar el tiempo de respuesta del servidor de cada host e identificar áreas de mejora Entre ellas tenemos las...Learn More
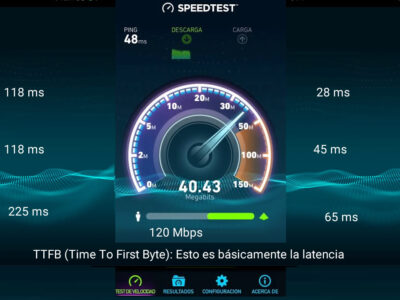
Test Velocidad CDN
🎯 GTmetrix (RECOMENDADO) gtmetrix.comTest desde: Vancouver, Dallas, Hong Kong, Londres, Mumbai, Sydney, São Paulo ⚡ Pingdom tools.pingdom.comTest desde: 7 ubicaciones incluyendo São...Learn More

Que es Soporte Web Perú
Que es Soporte Web Perú Soporte web Perú se refiere al conjunto de servicios y recursos que se proporcionan a los usuarios...Learn More

Plugins para WordPress Optimizacion Seguridad SEO
Optimizacion Seguridad SEO WordPress Optimización, Seguridad, SEO WordPress: Al tener un sitio web, llamada generalmente pagina web por los usuarios, no solamente...Learn More